Multi-threaded QuickSort
I complained recently, that C++, even on steroids of the new standard, still discourages concurrency and multithreading. In the attempt to break this ice in my heart, I’ve tried implementing the multi-threaded QuickSort. After partitioning we can sort sub-arrays in separate threads.
This is my naive approach:
int naive_quick_sort(std::vector<Type>::iterator begin, std::vector<Type>::iterator end) { auto const sz = end - begin; if (sz <= 1) return 0; auto pivot = begin + sz/2; auto const pivot_v = *pivot; std::swap(*pivot, *(end - 1)); auto p = std::partition(begin, end, [&](const Type& a) { return a < pivot_v; } ); std::swap(*p, *(end - 1)); if (sz > 4096) { auto left = std::async(std::launch::async, [&]() { return naive_quick_sort(begin, p); }); naive_quick_sort(p + 1, end); } else { naive_quick_sort(begin, p); naive_quick_sort(p + 1, end); } return 0; } void quick_sort(std::vector<Type>& arr) { naive_quick_sort(arr.begin(), arr.end()); }
Everything is simple, but it’s worth to consider some details. This is a threshold, 4096, determining when we switch the parallelism off. Why 4096? Just a guess, without a particular explanation.
Benchmark
The are three candidates:
- the naive implementation (using
async) - the same naive implementation, but single threaded (replace
if (sz > 4096)toif (false)) - std::sort() (replace
naive_quick_sort(arr.begin(), arr.end())tostd::sort(arr.begin(), arr.end()))
We sort an array of 50000000 elements of the type int64 (signed) with 10 runs and take an average. The values are random:
std::tr1::uniform_int<Type> uniform( std::numeric_limits<Type>::min(), std::numeric_limits<Type>::max()); std::mt19937_64 engine; void generate(std::vector<Type>& v) { std::for_each(v.begin(), v.end(), [](Type& i) { i = uniform(engine); }); }
Don’t ask me, why I convert the data between big and little endians back and fourth. It was implemented to compare this implementation with another one, in Java. In measurements we count only the “pure” time.
The compiler is VS 2011, 64-bit. CPU Intel Core i5 2.53GHz, 4 cores.
Iteration With async() One thread std::sort()
--------- --------------- ------------ ------------
1 2512 6555 7309
2 2337 6320 6977
3 2450 6516 7180
4 2372 6388 6933
5 2387 7074 7189
6 2339 7399 7040
7 2434 6875 7040
8 2562 7060 7187
9 2470 7050 7145
10 2422 6846 6898
--------- --------------- ------------ ------------
Среднее 2428.5 6808.3 7089.8
The time is in milliseconds.
It turns out that the naive implementation based on async() is three times faster then the single threaded std::sort(). A weird slowdown of the std::sort() against my naive single thread version can be explained, perhaps, that the data I generated is good, and my naive implementation is just lucky.
Any practical use out of it at all? Probably not. It is difficult to predict the behaviour of the implementation on different sets of data. For example, how to choose the threshold properly? Is it worth to start using thread pools?
The full source is below, including the generator.
Build and generate the data:
call "%VS110COMNTOOLS%..\..\VC\vcvarsall.bat" amd64 && ^
cl /Ox /DWIN32 sort_async.cpp && ^
sort_async generate
Warning! It generates 8GB of data.
Build and test:
call "%VS110COMNTOOLS%..\..\VC\vcvarsall.bat" amd64 && ^
cl /Ox /DWIN32 sort_async.cpp && ^
sort_async
File sort_async.cpp:
#include <vector> #include <iostream> #include <fstream> #include <sstream> #include <algorithm> #include <iomanip> #include <future> #include <random> #include <chrono> #include <cstdlib> const int ITERATIONS_NUM = 10; const int DATA_SIZE = 50000000; typedef __int64 Type; inline void endian_swap(Type& x) { x = (0x00000000000000FF & (x >> 56)) | (0x000000000000FF00 & (x >> 40)) | (0x0000000000FF0000 & (x >> 24)) | (0x00000000FF000000 & (x >> 8)) | (0x000000FF00000000 & (x << 8)) | (0x0000FF0000000000 & (x << 24)) | (0x00FF000000000000 & (x << 40)) | (0xFF00000000000000 & (x << 56)); } std::tr1::uniform_int<Type> uniform( std::numeric_limits<Type>::min(), std::numeric_limits<Type>::max()); std::mt19937_64 engine; void generate(std::vector<Type>& v) { std::for_each(v.begin(), v.end(), [](Type& i) { i = uniform(engine); }); } void check_sorted(const std::vector<Type>& v, const std::string& msg) { for (auto i = 0; i < v.size() - 1; ++i) { if (v[i] > v[i + 1]) { std::cout << "\nUnsorted: " << msg << "\n"; std::cout << "\n" << i << "\n"; std::cout << v[i] << " " << v[i + 1] << "\n"; std::exit(1); } } } std::string data_file_name(const int i, const std::string& suffix) { std::ostringstream fmt; fmt << "trash_for_sort_" << i << suffix << ".bin"; return fmt.str(); } void save_file(std::vector<Type> array, const std::string& name) { std::for_each(array.begin(), array.end(), [](Type& i) { endian_swap(i); }); std::ofstream os(name.c_str(), std::ios::binary|std::ios::out); auto const bytes_to_write = array.size() * sizeof(array[0]); std::cout << "Saving " << array.size() << " bytes to " << name << "\n"; os.write((char *)&array[0], bytes_to_write); } int main_generate(int argc, char* argv[]) { std::cout << "Generation\n"; for (auto i = 0; i < ITERATIONS_NUM; ++i) { std::vector<Type> unsorted(DATA_SIZE); generate(unsorted); save_file(unsorted, data_file_name(i, "")); std::cout << "Sorting...\n"; std::sort(unsorted.begin(), unsorted.end()); check_sorted(unsorted, "check sorted array"); save_file(unsorted, data_file_name(i, "_sorted")); } return 0; } void load_file(std::vector<Type>& array, const std::string& name) { std::cout << "Loading " << name; array.resize(DATA_SIZE, 0); std::ifstream is(name.c_str(), std::ios::binary|std::ios::in); auto const to_load = array.size() * sizeof(array[0]); is.read((char *)&array[0], to_load); if (is.gcount() != to_load) { std::cerr << ", Bad file " << name << ", loaded " << is.gcount() << " words but should be " << to_load << "\n"; std::exit(1); } std::for_each(array.begin(), array.end(), [](Type& v){ endian_swap(v); }); } int naive_quick_sort(std::vector<Type>::iterator begin, std::vector<Type>::iterator end) { auto const sz = end - begin; if (sz <= 1) return 0; auto pivot = begin + sz/2; auto const pivot_v = *pivot; std::swap(*pivot, *(end - 1)); auto p = std::partition(begin, end, [&](const Type& a) { return a < pivot_v; } ); std::swap(*p, *(end - 1)); if (sz > 4096) { auto left = std::async(std::launch::async, [&]() { return naive_quick_sort(begin, p); }); naive_quick_sort(p + 1, end); } else { naive_quick_sort(begin, p); naive_quick_sort(p + 1, end); } return 0; } void quick_sort(std::vector<Type>& arr) { naive_quick_sort(arr.begin(), arr.end()); } int main(int argc, char* argv[]) { if (argc == 2 && !std::strcmp(argv[1], "generate")) return main_generate(argc, argv); std::vector<double> times; auto times_sum = 0.0; for (auto i = 0; i < ITERATIONS_NUM; ++i) { std::vector<Type> unsorted; load_file(unsorted, data_file_name(i, "")); std::vector<Type> verify; std::cout << ", "; load_file(verify, data_file_name(i, "_sorted")); check_sorted(verify, "verify array"); std::cout << ", Started"; auto start = std::chrono::high_resolution_clock::now(); quick_sort(unsorted); auto stop = std::chrono::high_resolution_clock::now(); std::cout << ", Stopped, "; auto duration = std::chrono::duration<double>(stop - start).count(); std::cout << duration; check_sorted(unsorted, "sorted array"); const auto match = unsorted == verify; std::cout << (match ? ", OK" : ", DON'T MATCH"); times.push_back(duration); times_sum += duration; std::cout << "\n"; } auto const average = times_sum / ITERATIONS_NUM; auto const max_element = *std::max_element(times.begin(), times.end()); auto const min_element = *std::min_element(times.begin(), times.end()); auto const average_fixed = (times_sum - max_element - min_element) / (ITERATIONS_NUM - 2); std::cout << "Average: " << average << "s, " << "Average without max/min: " << average_fixed << "s." << std::endl; }
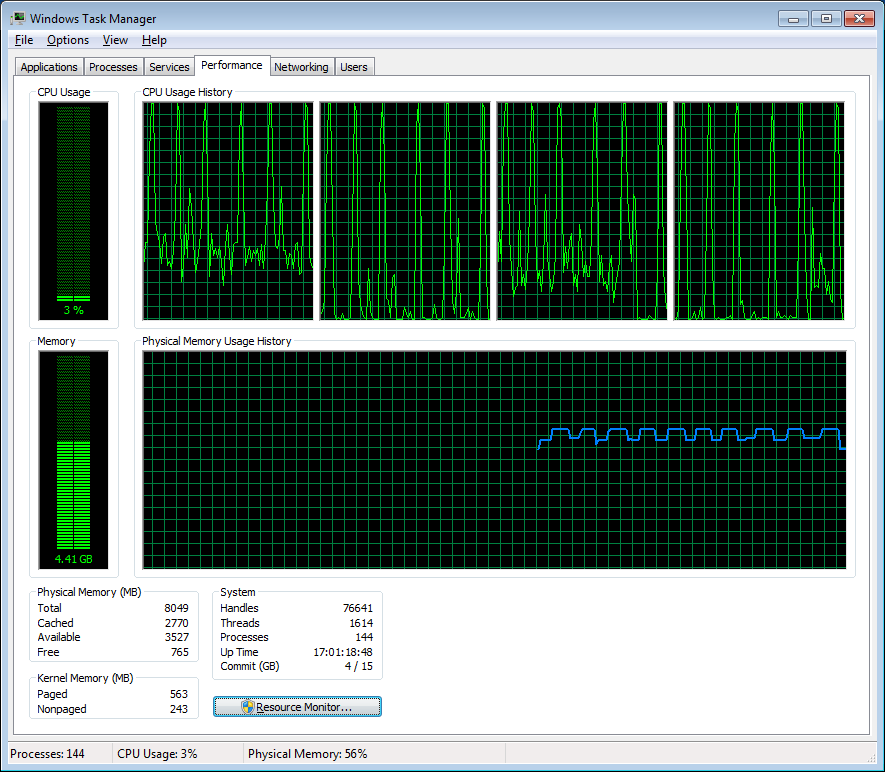
Finally, a CPU utilization graph. We see 100% spikes on each iteration.
Update
There is an article from Microsort, “Dynamic Task Parallelism”, also showing how to implement multithreaded Quicksort.
Disclaimer